MALMM: Multi-Agent Large Language Models for
Zero-Shot Robotic Manipulation
Abstract
Large Language Models (LLMs) have demonstrated remarkable planning abilities across various domains, including robotic manipulation and navigation. While recent work in robotics deploys LLMs for high-level and low-level planning, existing methods often face challenges with failure recovery and suffer from hallucinations in long-horizon tasks. To address these limitations, we propose a novel multi-agent LLM framework, Multi-Agent Large Language Model for Manipulation (MALMM). Notably, MALMM distributes planning across three specialized LLM agents, namely high-level planning agent, low-level control agent, and a supervisor agent. Moreover, by incorporating environmental observations after each step, our framework effectively handles intermediate failures and enables adaptive replanning. Unlike existing methods, MALMM does not rely on pre-trained skill policies or in-context learning examples and generalizes to unseen tasks. In our experiments, MALMM demonstrates excellent performance in solving previously unseen long-horizon manipulation tasks, and outperforms existing zero-shot LLM-based methods in RLBench by a large margin. Experiments with the Franka robot arm further validate our approach in real-world settings.
MALMM
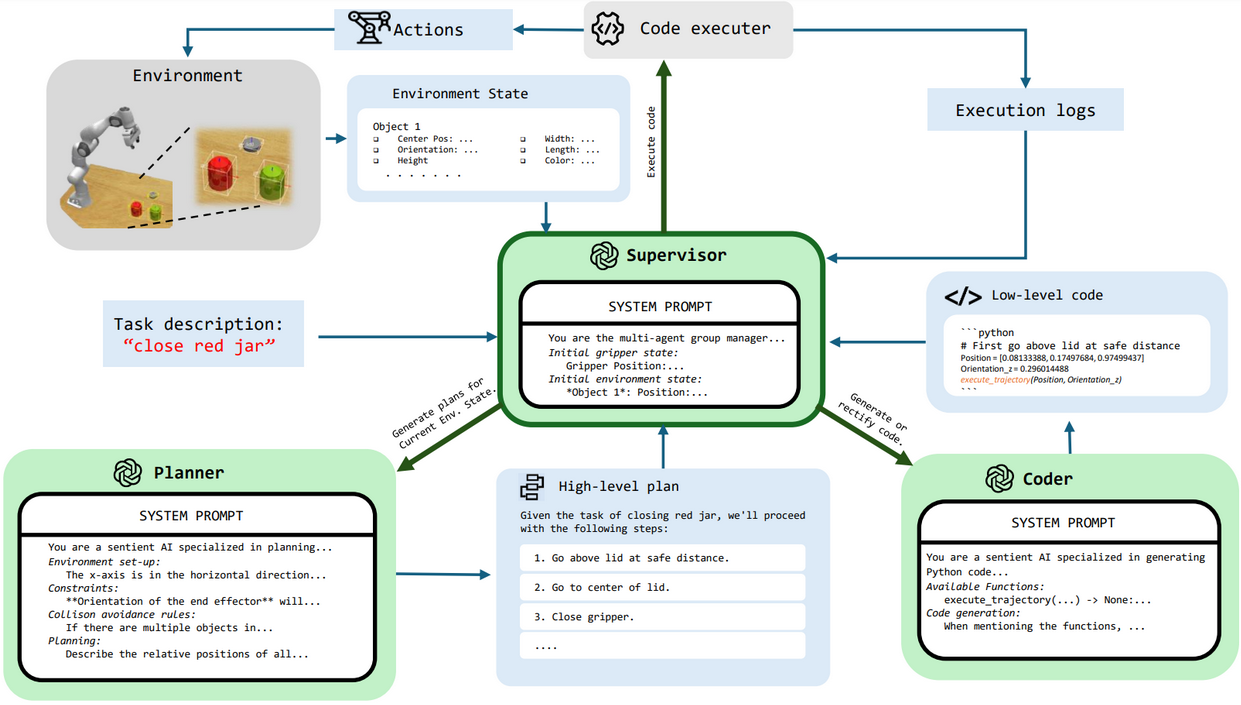
An overview of our multi-agent system, MALMM , consists of three LLM agents—Planner, Coder, and Supervisor—and a Code executor tool. Each agent operates with a specific system prompt defining its role: (1) the Planner generates high-level plans and replans in case of intermediate failures, (2) the Coder converts these plans into low-level executable code, and (3) the Supervisor coordinates the system by managing the transitions between the Planner, Coder, and Code executor.
Results

The Table shows the success rate for zero-shot evaluation on RLBench: The table highlights the best-performing method for each task in bold and the second-best-performing method is underlined. Symbols: † denotes LLaMA-3.3-70B as a base model, ‡ denotes GPT-4-Turbo as a base model.
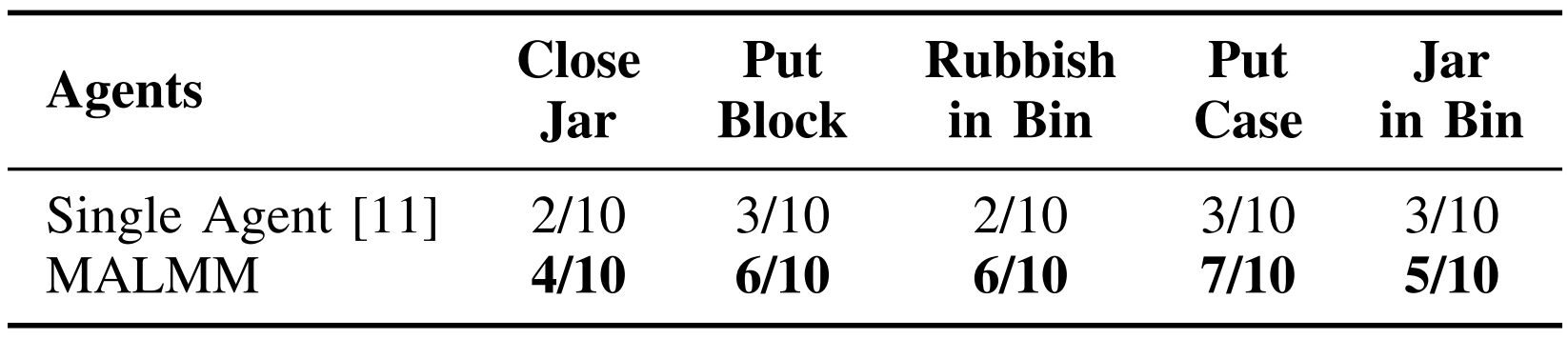
In this table, we do a Comparison of Single Agent and MALMM in a real-world Franka robot arm environment.